Research Questions and Findings
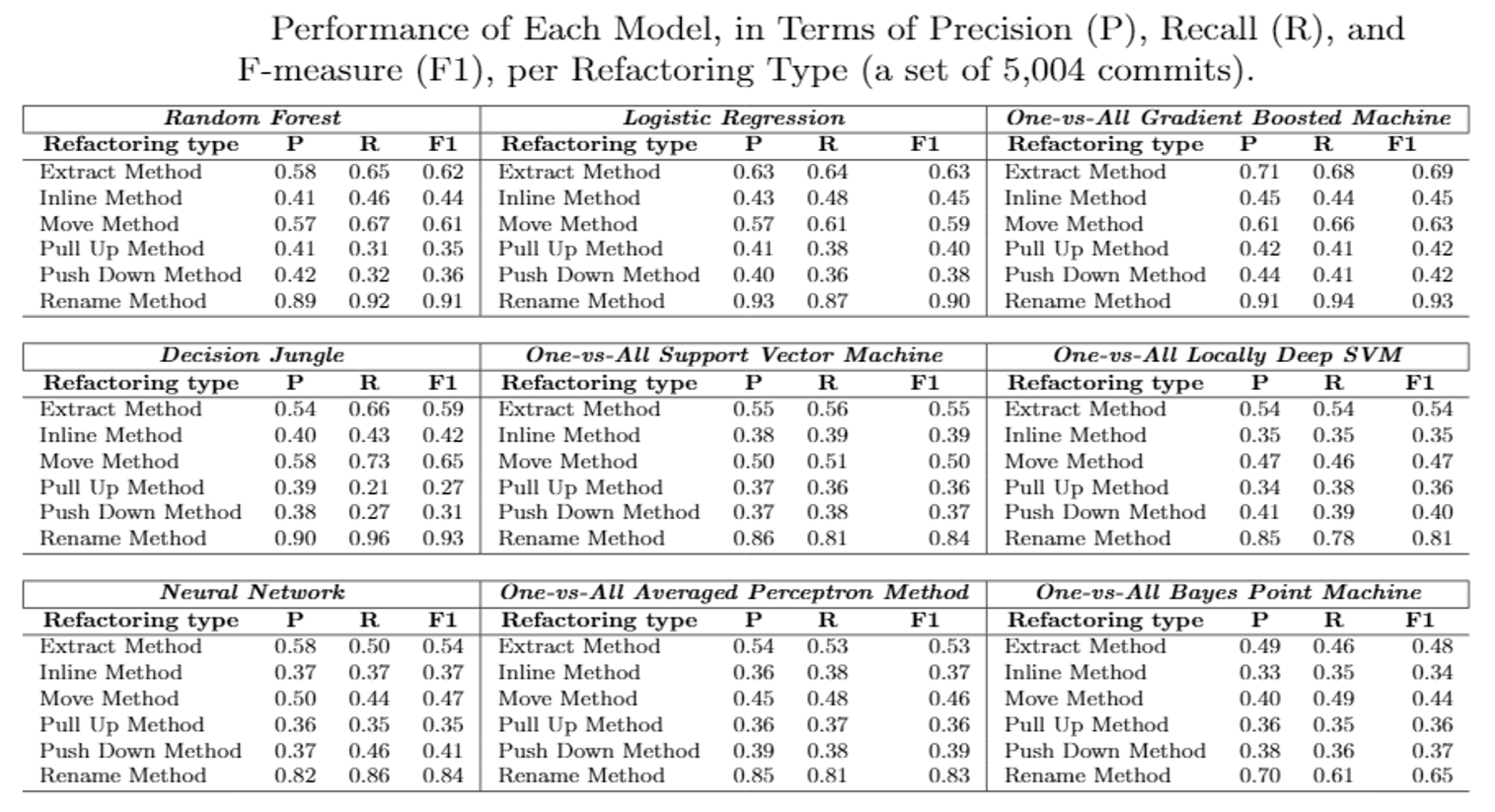
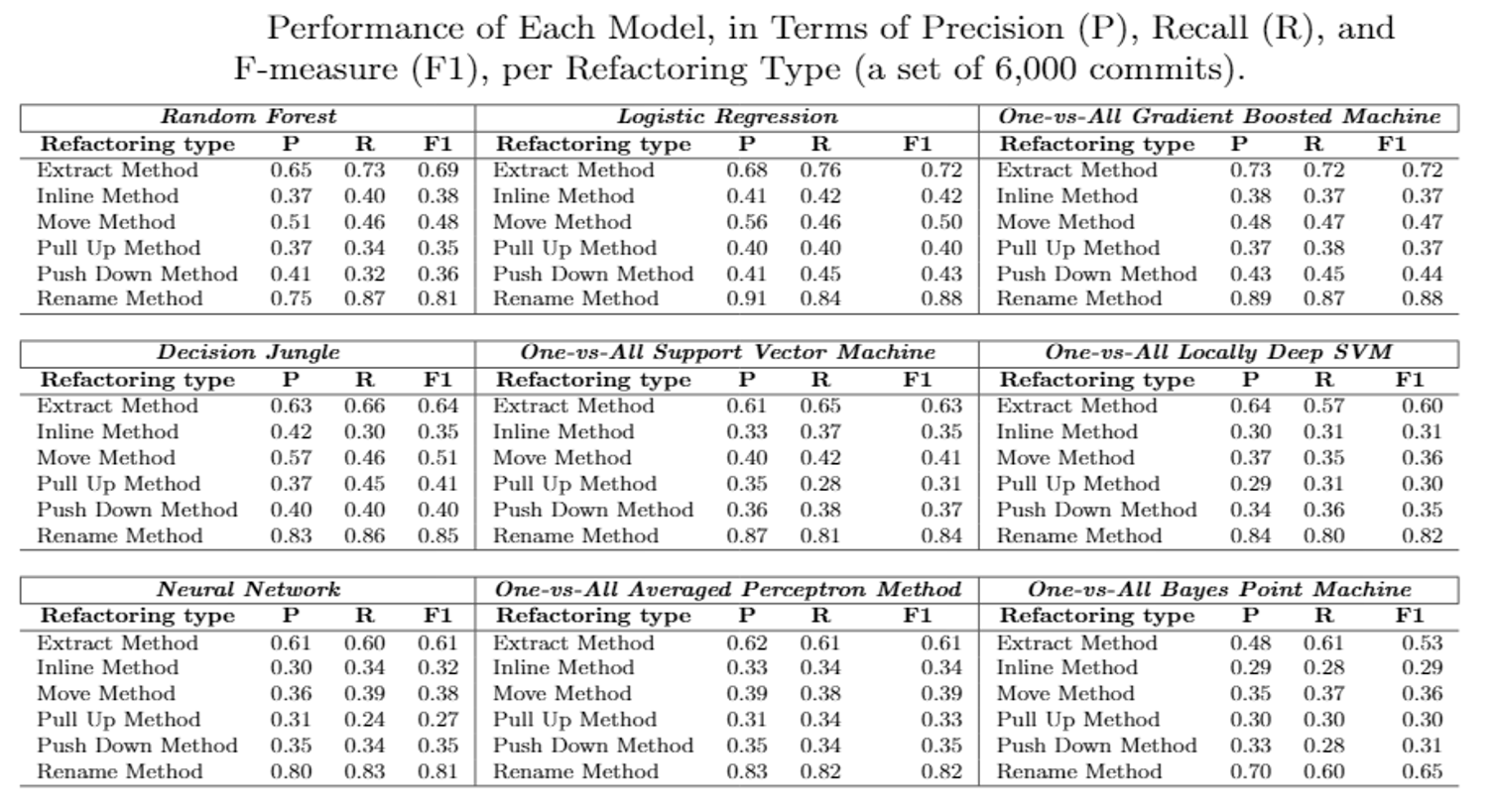
RQ1. How effective is our supervised learning in predicting the type of refactoring?
The accuracy of refactoring prediction is not uniform across all types. Some types are easier to predict than others. The prediction results for Rename Method, Extract Method, and Move Method was ranging from 63% to 93% in terms of F-measure. However, our model was not able to accurately distinguish between Inline Method, Pull-up Method, and Push-down Method, as its F-measure was between 42% and 45%.
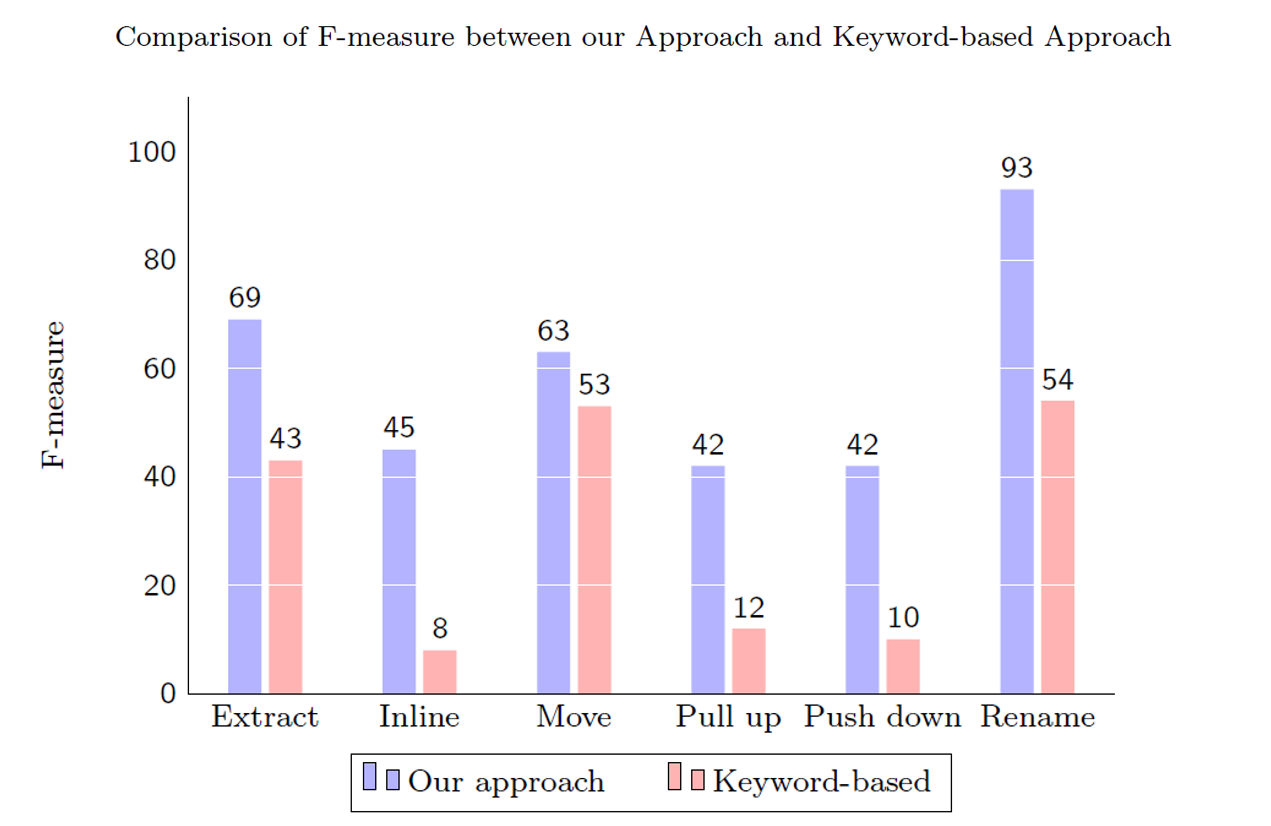
RQ2. How do our model compare with keyword-based classification?
The keyword-based approach performs significantly lower than ML models. It assumes that developers are familiar with the catalog of refactorings, or refactoring types being offered in the IDEs. Our findings show that developers tend to document refactoring using the same set of patterns. The keyword-based approach scored relatively better performance for the Rename Method type because its keyword (i.e., rename) is intuitive, in contrast with other types, such as Inline Method and Push-down Method.
RQ3. What are the frequent terms utilized by developers when documenting refactoring types?
Developers discriminate against different refactoring types through human language descriptions. The terminology used in rename refactorings are the most discriminative, indicating that these terms are strongly associated with the action of renaming.
RQ4. How useful is our approach in alerting the inconsistency types between source code and documentation?
Our model can work in conjunction with refactoring detectors in order to report any early inconsistency between refactoring types and their documentation..