Code Review Practices for Refactoring Changes: An Empirical Study on OpenStack
Understanding the practice of refactoring code review is of paramount importance to the research community and industry. Although Modern Code Review (MCR) is widely adopted in open-source and industrial projects, the relationship between code review and refactoring practice remains largely unexplored. In this study, we performed a quantitative and qualitative study to investigate the challenges faced by developers when reviewing refactorings.
More specifically, the research questions that we investigated are:
RQ1. How do refactoring reviews compare to non-refactoring reviews in terms of code review efforts?
This research question compares refactoring and non-refactoring reviews based on set of metrics. As we calculate the metrics of refactoring and non-refactoring reviews, we want to distinguish, for each metric, whether the variation is statistically significant.
RQ2. What are the criteria that mostly associated with refactoring review decision?
This research question explores the review criteria to assess refactoring changes.
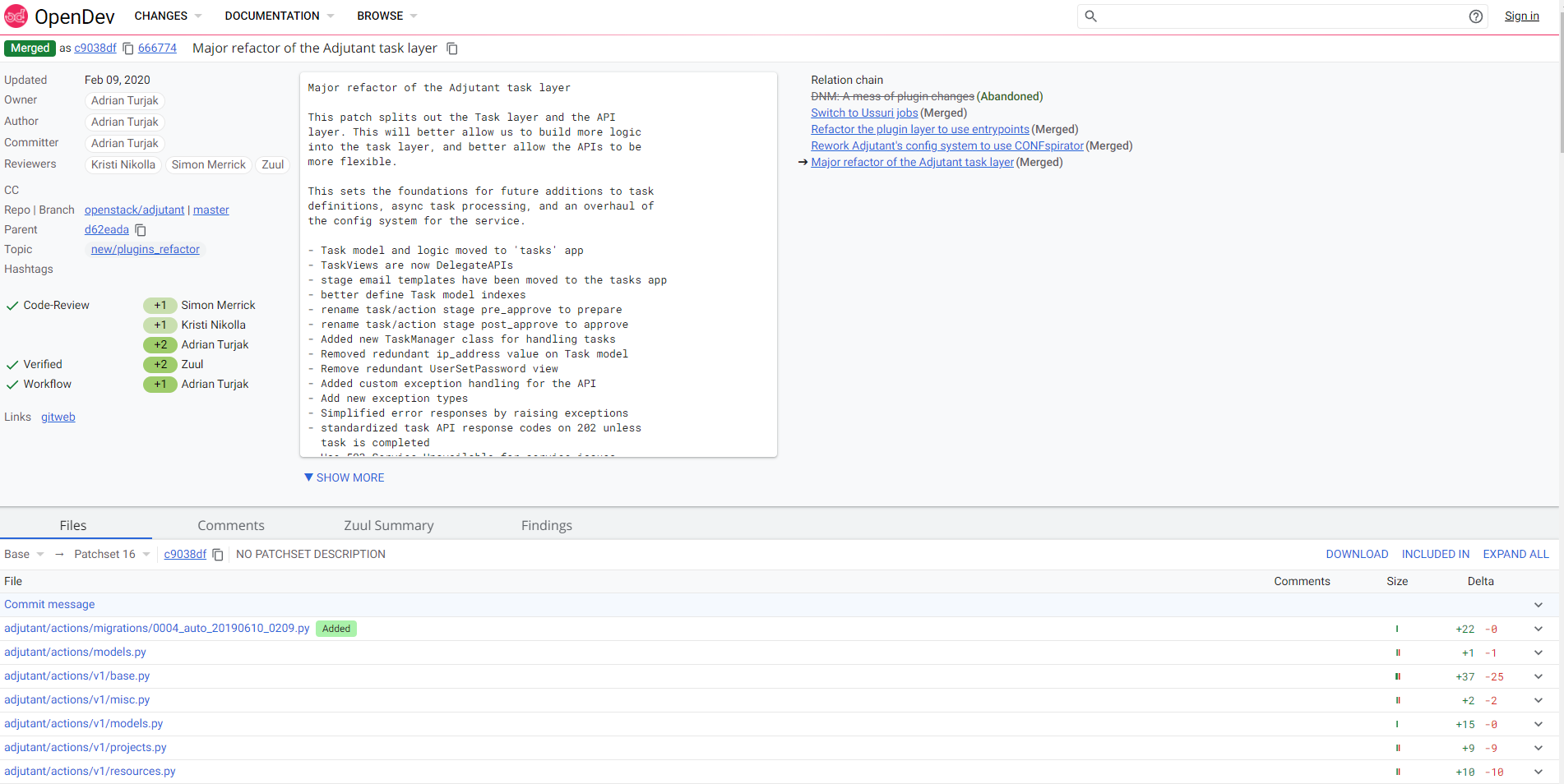
Example of a code review from OpenStack project using Gerrit:
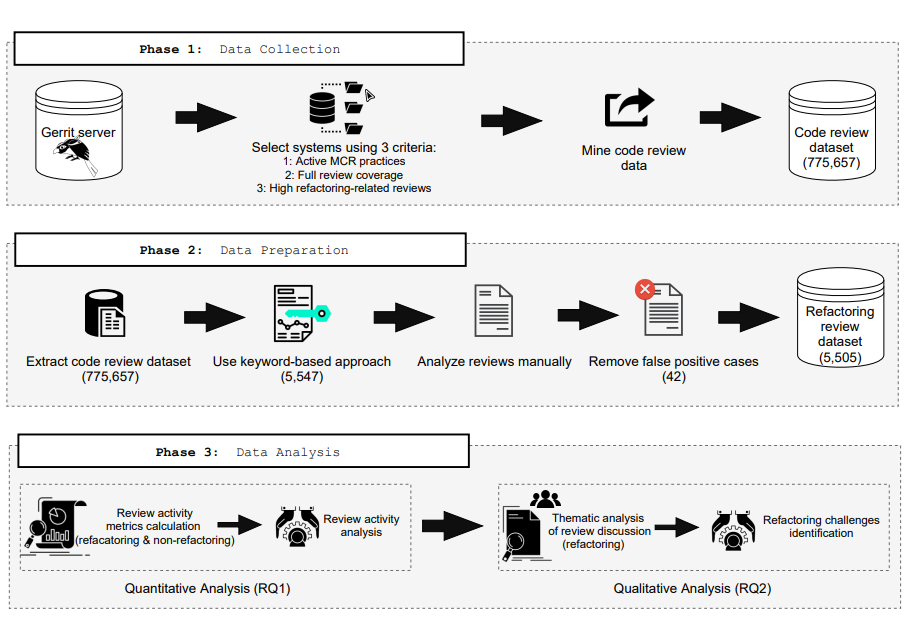
Approach:
Replication Package:
A replication package containing both the datasets and the scripts that were used for our analysis can be found here. More specifically, the link includes the following material:- "openstack-repositories-to-clone.txt" - A file containing the OpenStack repositories to be cloned using Gerrit miner.
- "preliminary_analysis.ipynb" - The Python Jupyter Notebook script that was used for the data collection process (i.e., refactoring reviews).
- "Code_reviews_analysis.ipynb" - The Python Jupyter Notebook script that was used to obtain code review mining results.
- "projects_stats.ipynb" - The Python Jupyter Notebook script that was used to obtain code repositories statistics.
- "Openstack-20211024T162557Z-004.zip" - A zip file containing all of the cloned OpenStack repositories.
- "Openstack_results_v2.sqlite" - The final dataset that was produced after the data preparation process.
- "RQ1.csv" - The dataset that was produced to answer the first research question along with the metrics definition and correlation analysis.
- "RQ2.csv" - The dataset that was produced to answer the second research question.
- "Survey.pdf" - List of survey questions used for the external validation.
- "Transcript.pdf" - Interview transcript for the external validation.
If you are interested to learn more about the process we followed, please refer to our paper.