Collected Data
On the Identification of Accessibility Bug Reports in Open Source Systems
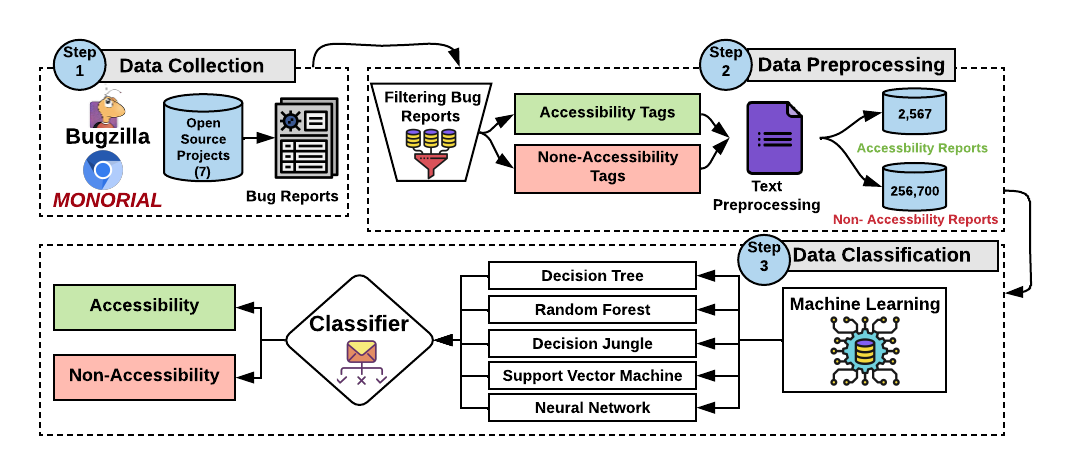
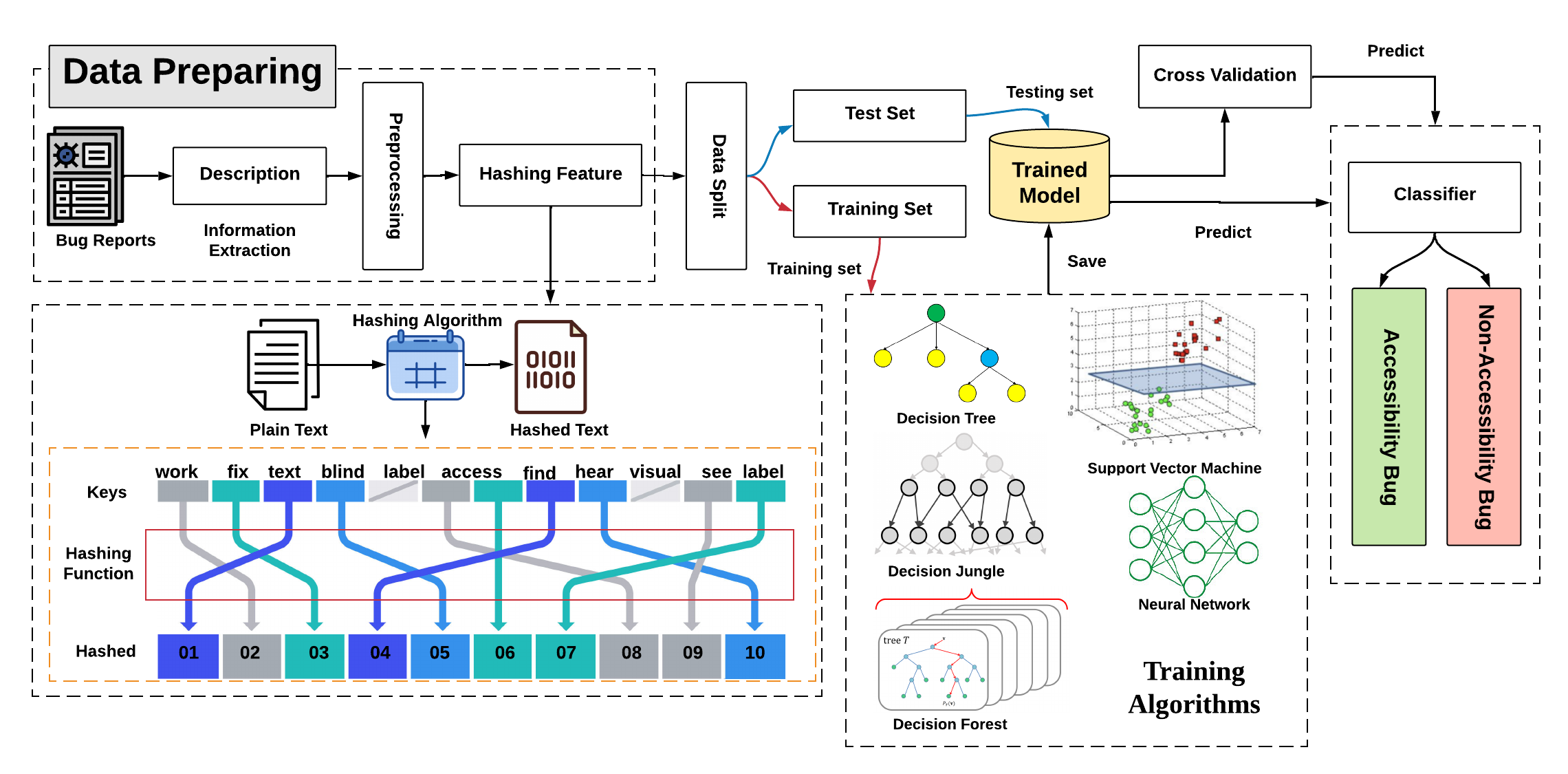
Manual inspection of a large number of bug reports to identify accessibility-related ones is time-consuming and error-prone. Prior research has investigated mobile app user reviews classification for various purposes, including bug reports identification, feature request identification, app performance optimization etc. Yet, none of the prior research has investigated the identification of accessibility-related bug reports, making their prioritization and timely correction difficult for software developers. To support developers with this manual process, the goal of this paper is to automatically detect, for a given bug report, whether it is about accessibility or not. Thus, we tackle the identification of accessibility bug reports as a binary classification problem. To build our model, we rely on an existing dataset of manually curated accessibility bug reports extracted from popular open-source projects, namely Mozilla Firefox and Google Chromium. We design our solution to learn from these reports the appropriate discriminative features i.e., keywords that properly represent accessibility issues. Our trained model is evaluating using stratified cross-validation, along with a comparison with various baselines models using keyword-based matching as a solution. Findings show that our classifier achieves high F1-scores of 93%.
More specifically, the research questions that we investigated are:
RQ1. Can we accurately detect accessibility - related bug reports?
Our aim is to design an approach that can automatically identify accessibility-related bug reports. Therefore, we put under test, various classifiers, such as neural networks, decision trees, and SVM, known to be efficient and widely used for binary classification problems. Answering to this research question would reveal the best performing model that we should deploy for our current problem, along with showing how much we can advance the state-of-the-art of detecting accessibility-related bug reports.
RQ2. What is the size of the training dataset needed for the classification to effectively identify accessibility bug reports?
After evaluating the accuracy of our model, we analyze the number of bug reports needed for training in order to achieve our optimal model classification accuracy. We anticipate our model to be easily exported and extended if it can achieve an acceptable performance using a relatively small set of training data. Otherwise, if the model requires a large number of bug reports, for training, then we report a need for a considerable time and effort for labeling.
If you are interested to learn more about the process we followed, please refer to our paper.
Related Paper
Wajdi Aljedaani, Mona Aljedaani, Eman Abdullah AlOmar, Mohamed Wiem Mkaouer, Stephanie Ludi, Yousef Bani Khalaf, "I Cannot See You—The Perspectives of Deaf Students to Online Learning during COVID-19 Pandemic: Saudi Arabia Case Study", Published at the Education Sciences Journal [preprint]
Eman Abdullah AlOmar, Wajdi Aljedaani, Murtaza Tamjeed, Mohamed Wiem Mkaouer, Yasmine N. El-Glaly, "Finding the Needle in a Haystack: On the Automatic Identification of Accessibility User Reviews", the international conference on Human-Computer Interaction (CHI'2021). [preprint]
Wajdi Aljedaani, Mohamed Wiem Mkaouer, Stephanie Ludi, Yasir Javed, "Automatic Classification of Accessibility User Reviews in Android Apps", Published at the 7th International Conference on Data Science and Machine Learning Applications (CDMA'22). [preprint]
Wajdi Aljedaani, Furqan Rustam, Stephanie Ludi, Ali Ouni, and Mohamed Wiem Mkaouer, "Learning Sentiment Analysis for Accessibility User Reviews", Published at the 36th IEEE/ACM International Conference on Automated Software Engineering Workshops (ASEW'21) [preprint]